In the CS publishing industry, normally people emphasize a lot on reproducibility of results. This usually entails that you need to open source your code, use public dataset, and disclose all the steps in your experiment, including data preparation, hyper-parameter configurations and using publicly available compute resources like GPUs.
What has transpired in the past decade or so in the deep learning world, however, is a trend towards satisfying those constraints and requirements at a superficial level, by cherry-picking results and baselines, without much regard to the actual practicality of the results published.
As a result, there has been a counter-force in the brewing over the past few years, where high profile companies like FAANG or MAANG are encouraged to submit their work to the so-called industrial track, with the aim to disseminate industry best practices backed by actual launches, with any unfair advantage of compute resources behind the work, as opposed to proof of concept paper mills that are used by tenure committees. I had the pleasure to participate in one of those. Granted they felt less self-contained, and rely on your personal credibility to make the case, nonetheless for someone not trained in the paper production industry, this is an invaluable way for me to share some insights quickly from the work I did.
Despite my own contribution, normally I don’t pay too much attention to these industry track papers because they usually just document some work history of highly paid ML employees in well established MAANG-like companies. But this week I ran into one on twitter that caught my attention: On the Factory Floor: ML Engineering for Industrial-Scale Ads Recommendation Models. I am personally well acquainted with two of the authors, and they are both highly accomplished at google. I also know enough about their career trajectories at google to understand the background of techniques they describe, especially the first half of the paper, which contains a lot of all-too-familiar strategies we tried at google search.
I am honestly pretty surprised that google these days allow such explicit technical details to be disclosed to the public. I guess they have come to realize that it’s the sheer volume of data that matters, not the actual ML design choices, at least not as much at this point. Without further ado, I will highlight some important excerpts I learned (or confirmed with my own shared experience) from that paper.
The entry point of discussion is a tradeoff between model efficiency and accuracy. In slightly more corporate ML language, accuracy is also known as quality, at least in the context of search relevance. The paper outlined a few tricks to reach higher tradeoff points between these two objectives, such as low rank bottleneck layer, something I learned there but did not see publicized widely. It then spends one subsection discussing AutoML which I thought it did a really great job.
Previously I felt unsure that AutoML would work at the scale outside google, and wasn’t completely sure how it works inside either. A similar direction called population based training or PBT for short, caught on for a while, especially by deepmind, then tapered off because it simply required too much compute power. I have a high school acquaintance who worked at Waymo and implemented the strategy successfully. But then she left and went back to google, or so I heard. But the AutoML approach taken by this paper felt very practical.
The basic idea is to have a pool of trainable weights, from which multiple different hyper-parameters being explored can share weights. Mathematically this does not make much sense, since an  matrix element of one model has nothing to do with the
matrix element of one model has nothing to do with the 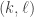 element of another.
element of another.
But that’s the beauty of deep learning, which I am reasonably familiar at this point. As long as the overall capacity adds up, parameter sharing or other approximate scheme might just work, and best of all, the theory is beautiful!
Another important area to trim excess model fat is data sampling, which the paper also devotes a full subsection. Indeed at google scale it is wise not to keep all samples, especially negative samples. This is also something I advocated at my current company: we should sample more potential positive examples for annotation, simply by keeping only the top k results according to current search ranking system, for a very small k say 2 or 3, instead of 10 or 20 that we are currently doing. Unfortunately such suggestion does not seem to resonate well with the crew or management. The paper does mention that multiple sampling strategies can be applied in conjunction, e.g., ones based on display UI, and another on logits and labels.
All of the above can be considered model efficiency/accuracy tradeoff. The next section deals exclusively with ways to improve accuracy, however, efficiency still needs to be considered obviously. There, the paper outlines 3 major techniques.
First comes loss engineering. This encompasses techniques like rank loss and distillation.
For rank loss, the basic idea is to use pairwise examples in conjunction with pointwise. Either the two losses share the same predictor, in which case some per example bias correction must be done, an idea I toyed with in multiple occasions but never saw it implemented. Or two separate predictors feed into the point-wise and pairwise losses separately. In that case the two predictors will share as many parameters as possible, so that the pairwise predictor (presumably not used at inference) will serve to regularize the point-wise predictor.
Distillation, especially the teacher/student kind, was something I witnessed at google. It felt impractical given that training a single teacher was expensive enough. Fortunately one could leverage the logged previous model score as a teacher for free. I believe that was the idea proposed here. In that case, indeed we only need to worry about student training cost.
Lastly curriculum learning was added as part of loss engineering as well. But that’s just a vast generalization of learning rate schedule. For instance, with multi-task learning, one could turn on certain task only after a certain number of steps. There is less mathematical elegance, but my own experience also suggests it’s pretty useful. For instance, one could free embeddings after a certain number steps to prevent the model from memorizing the training data.
A second pillar of accuracy improvement is the introduction of second order optimizer, pioneered by Rohan Anil in his earlier paper on the Shampoo optimizer. The basic idea as I understood it is that instead of computing the full Hessian matrix, we only compute the restricted ones for each meaningful block of weights, for instance, a kernel matrix or a bias vector. It’s not clear if they have tried LBFGS or other classical low rank approximation techniques even on top of such restricted Hessian setup, but the overall efficiency/accuracy tradeoff reported is decent: +0.44% accuracy (compared to 0.1% for normal launches) vs +10% training cost. Still I suspect this launch was a bit contentious and nerve-wrecking for some.
Deep Cross (detailed in DCNv2) was the last area of improvement mentioned. There is very little mathematical elegance, and the gain looks smallish too. The paper was pretty honest about that, but does a good job summarizing the main idea within a single paragraph. It also mentions a bunch of localized tricks that seem needed for Deep Cross to work well, including AutoML and curriculum ramping.
The last three sections deal with more esoteric optimization objectives, such as model reproducibility/robustness and calibration/credit attribution. Strangely, the paper divides calibration/attribution into two sections, one discussing the problem itself, and the other the proposed solution. I also spent the most time puzzling over various sentences among these 3 sections, both because I work less in those areas, also that the objective is less well-defined, or needs to be defined by the problem solver him/her-self.
TBC

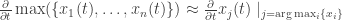
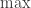 operator is the same as top-k for
operator is the same as top-k for 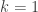 . The above equality is approximate because the
. The above equality is approximate because the 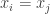 for some
for some  . However this happens also for ReLU and with zero probability at any given point in training, so we consider it a harmless approximation.
. However this happens also for ReLU and with zero probability at any given point in training, so we consider it a harmless approximation. above. By doing that, you achieve exact sampling according to the probability distribution given by a suitably normalized
above. By doing that, you achieve exact sampling according to the probability distribution given by a suitably normalized 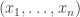 . This is intuitively clear, since the higher
. This is intuitively clear, since the higher 
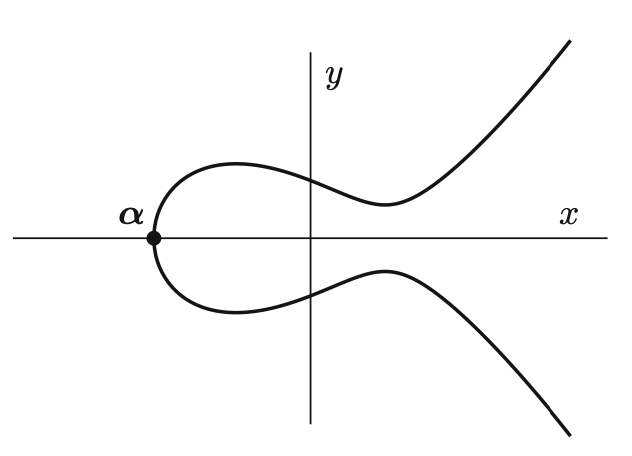
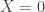 because of the equation
because of the equation 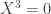 , even though it corresponds to the intersection of the lines
, even though it corresponds to the intersection of the lines  with the line at infinity. The reason for the apparent contradiction
with the line at infinity. The reason for the apparent contradiction  is that for points at infinity, we only consider the asymptotic directions, not the actual point. Because
is that for points at infinity, we only consider the asymptotic directions, not the actual point. Because  grows faster than
grows faster than  as they approach infinity on the cubic curve,
as they approach infinity on the cubic curve, 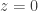 . The inflection point can also be verified by looking at the
. The inflection point can also be verified by looking at the 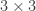 Hessian.
Hessian. 